Compiler Design and Construction 2071-I
Attempt all questions. (10x6=60)
1. Explain the various phases of compiler in detail with practical example.
A compiler operates in phases. A phase is a logically interrelated operation that takes source program in one representation and produces output in another representation. The phases of a compiler are shown in below:
1. Analysis phase breaks up the source program into constituent pieces and creates an intermediate representation of the source program. Analysis of source program includes: lexical analysis, syntax analysis and semantic analysis.
2. Synthesis phase construct the desired target program from the intermediate representation. The synthesis part of compiler consists of the following phases: Intermediate code generation, Code optimization and Target code generation.
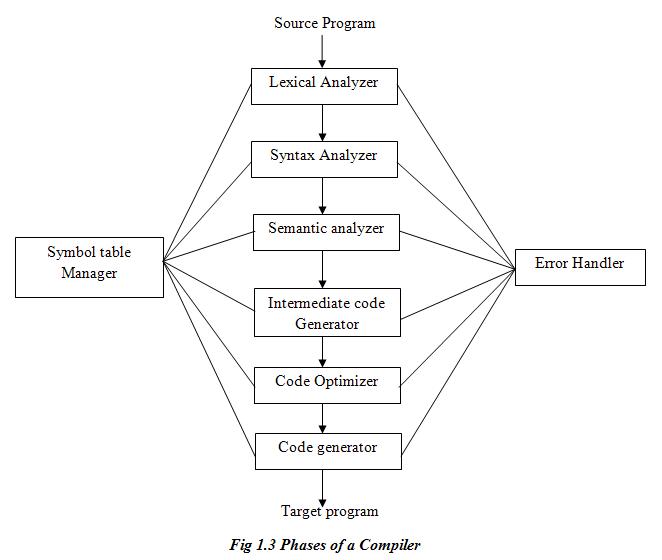
1. Lexical Analysis:
In this phase, lexical analyzer reads the source program and returns the tokens of the source program. Token is a sequence of characters that can be treated as a single logical entity (such as identifier, operators, keywords, constants etc.).
Example:
Input String: c = a + b * 3
Tokens: id1 = id2 + id3 * 3
2. Syntax Analysis:
In this phase, the syntax analyzer takes the token produced by lexical analyzer as input and generates a parse tree as output. In syntax analysis phase, the parser checks that the expression made by the token is syntactically correct or not, according to the rules that define the syntax of the source language.
Example:

3. Semantic Analysis:
In this phase, the semantic analyzer checks the source program for semantic errors and collects the type information for the code generation. Semantic analyzer checks whether they form a sensible set of instructions in the programming language or not. Type-checking is an important part of semantic analyzer.
Example:

4. Intermediate Code Generation:
If the program syntactically and semantically correct then intermediate code generator generates a simple machine independent intermediate language. The intermediate code should be generated in such a way that it can easily translated into the target machine code.
Example:
t1 = 3.0;
t2 = id3 * t1;
t3 = id2 + t2;
id1 = t3;
5. Code Optimization:
It is used to improve the intermediate code so that the output of the program could run faster and takes less space. It removes the unnecessary lines of the code and arranges the sequence of statements in order to speed up the program execution without wasting resources.
Example:
t2 = id3 * 3.0;
id1 = id2 + t2;
6. Code Generation:
Code generation is the final stage of the compilation process. It takes the optimized intermediate code as input and maps it to the target machine language.
Example:
MOV R1, id3
MUL R1, #3.0
MOV R2, id2
ADD R1, R2
MOV id1, R1
Symbol Table
Symbol tables are data structures that are used by compilers to hold information about source-program constructs. The information is collected incrementally by the analysis phase of compiler and used by the synthesis phases to generate the target code. Entries in the symbol table contain information about an identifier such as its type, its position in storage, and any other relevant information.
Error Handling
Whenever an error is encountered during the compilation of the source program, an error handler is invoked. Error handler generates a suitable error reporting message regarding the error encountered.
2. Explain about design of lexical analyzer generator with its suitable diagram.
Lexical Analyzer Generator (Lex/Flex) systematically translate regular definitions into C source code for efficient scanning. Generated code is easy to integrate in C applications. Flex is a latter version of lex.

- Firstly, specification of a lexical analyzer is prepared by creating a program lex.l in Lex/Flex
- lex.l is run into lex compiler to produce a C program lex.yy.c
- lex.yy.c consists of the tabular representation of lex.l, together with a standard routine that uses the table to recognize lexeme.
- Lex.yy.c is run through C compiler to produce the object program a.out which is a lexical analyzer that input into tokens.
A flex specification consists of three parts:
1. regular definitions, C declarations in %{ %}
%%
2. translation rules
%%
3. user-defined auxiliary procedures
The translation rules are of the form:
p1 { action1 }
p2 { action2 }
…
pn { actionn }
Lex/flex regular definitions are of the form:
name definition
E.g. Digit [0-9]
Example of lex specification
%{
#include <stdio.h>
%}
%%
[0-9]+ { printf(“%s\\n”, yytext); }
. | \\n { }
%%
main()
{ yylex();
}
3. What are the problem with top down parsers? Explain the LR parsing algorithm.
Top-down parser is the parser which generates parse for the given input string with the help of grammar productions by expanding the non-terminals i.e. it starts from the start symbol and ends on the terminals.
Problems with top-down parsers are:
- Only judges grammatically
- Stops when it finds a single derivation.
- No semantic knowledge employed.
- No way to rank the derivations.
- Problems with left-recursive rules.
- Problems with ungrammatical sentences.
LR Parsing algorithm:
An LR parser comprises of a stack, an input buffer and a parsing table that has two parts: action and goto. Its stack comprises of entries of the form so X1 s1 X2s2 ... Xm sm where every si is called a state and every Xi is a grammar symbol(terminal or non-terminal)
If top of the stack is Sm and input symbol is a, the LR parser consults action[sm,a] which can be one of four actions.
1. Shift s , where s is a state.
2. Reduce using production A→ b
3. Accept
4. Error
The function goto takes a state and grammar symbol as arguments and produces a state.
The configuration of the LR parser is a tuple comprising of the stack contents and the contents of the unconsumed input buffer. It is of the form
(so X1 s1 X2s2 ... Xm sm , ai ai+1 ... an $)
1. If action[sm,ai] = shift s, the parser executes a shift move entering the configuration
(so X1 s1 X2s2 ... Xm smais , ai+1 ... an $) shifting both ai and the state s onto stack.
2. If action[sm,ai] = reduce A→ β , the parser executes a reduce move entering the configuration
(so X1 s1 X2s2 ... Xm-r sm-r As , ai ai+1 ... an $) . Here s = goto[sm-r,A] and r is the length of handle β.
Note: if r is the length of β then the parser pops 2r symbols from the stack and push the state as on goto[sm-r,A] . After reduction , the parser outputs the production used on reduce operation. A→β
3. If action[sm,ai] = Accept, then parser accept i.e. parsing successfully complete and stop.
4. If action[sm,ai] = error then call the error recovery routine.
4. Define finite automata. Construct a finite automata that will accept a string at zeros and ones that contains an odd number of zeros and an even number of ones.
A finite automaton is a mathematical (model) abstract machine that has a set of "state" and its "control" moves from state to state in response to external "inputs". The control may be either "deterministic" meaning that the automation can‘t be in more than one state at any one time, or "non-deterministic", meaning that it may be in several states at once. This distinguishes the class of automata as DFA or NFA.
- The DFA, i.e. Deterministic Finite Automata can‘t be in more than one state at any time.
- The NFA, i.e. Non-Deterministic Finite Automata can be in more than one state at a time.
Now,
DFA that will accept a string at zeros and ones that contains an odd number of zeros and an even number of ones is shown below:

Here,
Q = {q0, q1, q2, q3}
∑ = {0, 1}
δ = Above transition diagram
q0 = q0
F = {q2}
5. What are the different issues in the design of code generator? Explain with example about the optimization of basic blocks.
The issues to code generator design includes:
1. Input to the code generator: The input to the code generator is intermediate representation together with the information in the symbol table. Intermediate representation has the several choices:
- Postfix notation,
- Syntax tree or DAG,
- Three address code
The code generation phase needs complete error-free intermediate code as an input requires.
2. Target Program: The target program is the output of the code generator. The output can be:
- Assembly language: It allows subprogram to be separately compiled.
- Relocatable machine language: It makes the process of code generation easier.
- Absolute machine language: It can be placed in a fixed location in memory and can be executed immediately.
3. Target Machine: Implementing code generation requires thorough understanding of the target machine architecture and its instruction set.
4. Instruction Selection: Efficient and low cost instruction selection is important to obtain efficient code. When we consider the efficiency of target machine then the instruction speed and machine idioms are important factors. The quality of the generated code can be determined by its speed and size.
5. Register Allocation: Proper utilization of registers improve code efficiency. Use of registers make the computations faster in comparison to that of memory, so efficient utilization of registers is important. The use of registers are subdivided into two subproblems:
- During Register allocation, we select only those set of variables that will reside in the registers at each point in the program.
- During a subsequent Register assignment phase, the specific register is picked to access the variable.
6. Choice of Evaluation order: The efficiency of the target code can be affected by the order in which the computations are performed.
Basic block optimization techniques are:
1. Common-Subexpression Elimination: In the common sub-expression, we don't need to be computed it over and over again. Instead of this we can compute it once and kept in store from where it's referenced when encountered again. For e.g.

2. Dead Code Elimination: The dead code may be a variable or the result of some expression computed by the programmer that may not have any further uses. By eliminating these useless things from a code, the code will get optimized. For e.g.

3. Renaming Temporary Variables: Temporary variables that are dead at the end of a block can be safely renamed. The basic block is transforms into an equivalent block in which each statement that defines a temporary defines a new temporary. Such a basic block is called normal-form block or simple block. For e.g.

4. Interchange of Statements: Independent statements can be reordered without effecting the value of block to make its optimal use. For e.g.

5. Algebraic Transformations: In the algebraic transformation, we can change the set of expression into an algebraically equivalent set. Simplify expression or replace expensive expressions by cheaper ones. For e.g.

6. What are the main issues involved in designing lexical analyzer? Mention the various error recovery strategies for a lexical analyzer.
Lexical analysis is the process of producing tokens from the source program. It has the following issues:
• Lookahead
• Ambiguities
1. Lookahead:
Lookahead is required to decide when one token will end and the next token will begin. The simple example which has lookahead issues are i vs. if, = vs. ==. Therefore a way to describe the lexemes of each token is required.
A way needed to resolve ambiguities
• Is if it is two variables i and f or if?
• Is == is two equal signs =, = or ==?
• arr(5, 4) vs. fn(5, 4) II in Ada (as array reference syntax and function call syntax are similar.
Hence, the number of lookahead to be considered and a way to describe the lexemes of each token is also needed.
2. Ambiguities:
The lexical analysis programs written with lex accept ambiguous specifications and choose the longest match possible at each input point. Lex can handle ambiguous specifications. When more than one expression can match the current input, lex chooses as follows:
• The longest match is preferred.
• Among rules which matched the same number of characters, the rule given first is preferred.
Error recovery strategies for a lexical analyzer
A character sequence that cannot be scanned into any valid token is a lexical error. Misspelling of identifiers, keyword, or operators are considered as lexical errors. Usually, a lexical error is caused by the appearance of some illegal character, mostly at the beginning of a token.
The following are the error-recovery strategies in lexical analysis:
1) Panic Mode Recovery: Once an error is found, the successive characters are always ignored until we reach a well-formed token like end, semicolon.
2) Deleting an extraneous character.
3) Inserting a missing character.
4)Replacing an incorrect character by a correct character.
5)Transforming two adjacent characters.
7. Define a context free grammar. What are the component of context free grammar? Explain.
A Context Free Grammar (CFG) is defined by 4-tuples as G = (V, T, P, S) where
- V is a finite set of variable symbols (Non-terminals)
- T is a finite set of terminal symbols.
- P is a set of production rules.
- S is a start symbol, S ∈ V
For e.g.
E → EAE | (E) | -E | id
A → + | - | * | /
Here, E and A are non-terminals with E as start symbol and other symbols are terminals.
The components of CFG are:
- A set of terminal symbols which are the characters that appear in the language/strings generated by the grammar. Terminal symbols never appear on the left-hand side of the production rule and are always on the right-hand side.
- A set of non-terminal symbols (or variables) which are placeholders for patterns of terminal symbols that can be generated by the non-terminal symbols. These are the symbols that will always appear on the left-hand side of the production rules, though they can be included on the right-hand side. The strings that a CFG produces will contain only symbols from the set of non-terminal symbols.
- A set of production rules which are the rules for replacing non-terminal symbols. Production rules have the following form: variable → string of variables and terminals.
- A start symbol which is a special non-terminal symbol that appears in the initial string generated by the grammar.
8. What are the various issues of code generator? Explain the benefits of intermediate code generation.
The issues to code generator design includes:
1. Input to the code generator: The input to the code generator is intermediate representation together with the information in the symbol table. Intermediate representation has the several choices:
- Postfix notation,
- Syntax tree or DAG,
- Three address code
The code generation phase needs complete error-free intermediate code as an input requires.
2. Target Program: The target program is the output of the code generator. The output can be:
- Assembly language: It allows subprogram to be separately compiled.
- Relocatable machine language: It makes the process of code generation easier.
- Absolute machine language: It can be placed in a fixed location in memory and can be executed immediately.
3. Target Machine: Implementing code generation requires thorough understanding of the target machine architecture and its instruction set.
4. Instruction Selection: Efficient and low cost instruction selection is important to obtain efficient code. When we consider the efficiency of target machine then the instruction speed and machine idioms are important factors. The quality of the generated code can be determined by its speed and size.
5. Register Allocation: Proper utilization of registers improve code efficiency. Use of registers make the computations faster in comparison to that of memory, so efficient utilization of registers is important. The use of registers are subdivided into two subproblems:
- During Register allocation, we select only those set of variables that will reside in the registers at each point in the program.
- During a subsequent Register assignment phase, the specific register is picked to access the variable.
6. Choice of Evaluation order: The efficiency of the target code can be affected by the order in which the computations are performed.
The given program in a source language is converted into an equivalent program in an intermediate language by the intermediate code generator. Intermediate codes are machine independent codes.
Benefits of intermediate code generation:
- If a compiler translates the source language to its target machine language without having the option for generating intermediate code, then for each new machine, a full native compiler is required.
- Intermediate code eliminates the need of a new full compiler for every unique machine by keeping the analysis portion same for all the compilers.
- It becomes easier to apply the source code modifications to improve code performance by applying code optimization techniques on the intermediate code.
9. Explain the peephole optimization. Write a three address code for the expression r:= 7*3+9.
Peephole optimization is a simple and effective technique for locally improving target code. This technique is applied to improve the performance of the target program by examining the short sequence of target instructions (called the peephole) and replace these instructions replacing by shorter or faster sequence whenever possible. Peephole is a small, moving window on the target program.
Peephole Optimization Techniques are:
1. Redundant load and store elimination: In this technique the redundancy is eliminated. For e.g.
Initial code:
y = x + 5;
i = y;
z = i;
w = z * 3;
Optimized code:
y = x + 5;
i = y;
w = y * 3;
Initial code:
x = 2 * 3;
Optimized code:
x = 6;
3. Strength Reduction: The operators that consume higher execution time are replaced by the operators consuming less execution time. For e.g.
Initial code:
y = x * 2;
Optimized code:
y = x + x;
4. Algebraic Simplification: Peephole optimization is an effective technique for algebraic simplification. The statements such as x = x + 0 or x = x * 1 can eliminated by peephole optimization.
5. Machine idioms: The target instructions have equivalent machine instructions for performing some operations. Hence we can replace these target instructions by equivalent machine instructions in order to improve the efficiency. For e.g., some machine have auto-increment or auto-decrement addressing modes that are used to perform add or subtract operations.
Given expression
r:= 7*3+9
Three address code for given expression:
t1 = 7 * 3
t2 = t1 + 9
r = t2
10. Differentiate between Pascal compiler and C++ compiler.
|
Pascal Compiler |
C/C++ Compiler |
|
It
is one pass compiler where all the phases are combined into one pass. |
It
is multi-pass compiler where different phases of compiler are grouped into
multiple phases. |
|
Here
intermediate representation of source program is not created. |
Here
intermediate representation of source program is created. |
|
It
is faster than C/C++ compiler. |
It
is slightly slower than Pascal compiler. |
|
It does not look
back at code it previously
processed |
Each pass takes
the result of the previous pass as the input and create intermediate output. |
|
Unable to
generate efficient programs due to limited scope available. |
Due to wider
scope availability, these compiler
allows better code generation |
|
It simplifies
the job of writing a compiler but limited. |
It is complex
job writing a multi-pass compiler, code is improved pass by pass until final
code. |
|
Memory
consumption is lower. |
Memory
consumption is higher. |