Compiler Design and Construction 2073
Attempt all questions. (10x6=60)
1. Draw block diagram to represent different phases of compiler. Explain different steps in analysis phase.
A compiler is a program that takes a program written in a source language and translates it into an equivalent program in a target language. As an important part of a compiler is error showing to the programmer.

Block diagram for phases of compiler:
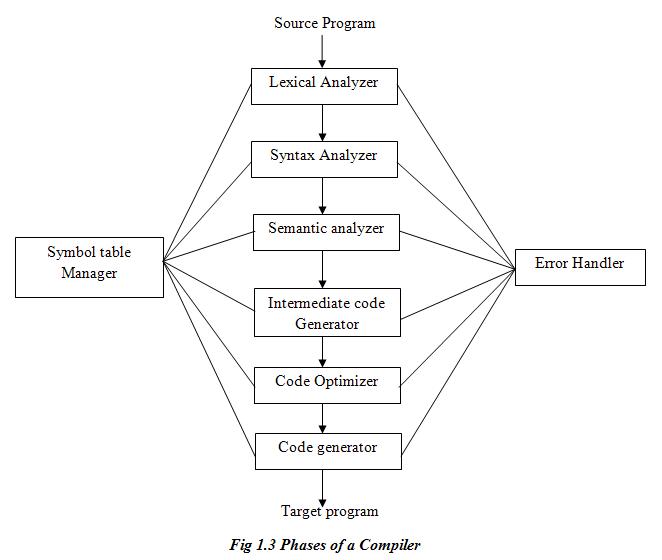
Analysis phase breaks up the source program into constituent pieces and creates an intermediate representation of the source program. Analysis of source program includes: lexical analysis, syntax analysis and semantic analysis.
1. Lexical Analysis:
In this phase, lexical analyzer reads the source program and returns the tokens of the source program. Token is a sequence of characters that can be treated as a single logical entity (such as identifier, operators, keywords, constants etc.).
2. Syntax Analysis:
In this phase, the syntax analyzer takes the token produced by lexical analyzer as input and generates a parse tree as output. In syntax analysis phase, the parser checks that the expression made by the token is syntactically correct or not, according to the rules that define the syntax of the source language.
3. Semantic Analysis:
In this phase, the semantic analyzer checks the source program for semantic errors and collects the type information for the code generation. Semantic analyzer checks whether they form a sensible set of instructions in the programming language or not. Type-checking is an important part of semantic analyzer.
Example of Analysis phase:


2. Convert the following RE to DFA directly.
(a+b)*ab
Given RE;
(a+b)*ab
The augmented RE of the given RE is:

Syntax tree for augmented R.E. is

Calculating followpos:
followpos(1) = {1, 2, 3}
followpos(2) = {1, 2, 3}
followpos(3) = {4}
followpos(4) = {5}
Now,
1) Start state of DFA = firstpos(root) = {1, 2, 3} = S0
Use followpos of symbol representing position in RE to obtain the next state of DFA.
2) From S0 = {1, 2, 3}
1 and 3 represents 'a'
2 represents 'b'
followpos({1, 3}) = {1, 2, 3, 4} = S1
δ(s0, a) = S1
followpos({2}) = {1, 2, 3} = S0
δ(S0, b) = S0
3) From S1 = {1, 2, 3, 4}
1, 3 → a
2, 4 → b
followpos({1, 3}) = {1, 2, 3, 4} = S1
δ(S1, a) = S1
followpos({2, 4}) = {1, 2, 3, 5} = S2
δ(S1, b) = S2
4) From S2 = {1, 2, 3, 5}
1, 3 → a
2 → b
5 → #
followpos({1, 3}) = {1, 2, 3, 4}= S1
δ(S2, a) = S1
followpos({2}) = {1, 2, 3} = S0
δ(S2, b) = S0
Now there was no new states occur.
Therefore, Final state = {S2}
Now the resulting DFA of given regular expression is:

3. Find first and follow of all the non terminals in the following grammar.

The given grammar is;
Now, the FIRST and FOLLOW of given non-terminals are:
FIRST(A) = FIRST(T) = FIRST(X) = {(, a}
FIRST(E) = {+, ∈}
FIRST(Y) = {*, ∈}
FOLLOW(A) = {), $}
FOLLOW(E) = {), $}
FOLLOW(T) = {), +, $}
FOLLOW(Y) = {), +, $}
FOLLOW(X) = {*, +, ), $}
|
Non-terminals |
FIRST() |
FOLLOW() |
|
A |
{(, a} |
{), $} |
|
E |
{+, ∈} |
{), $} |
|
T |
{(, a} |
{), +, $} |
|
Y |
{*, ∈} |
{), +, $} |
|
X |
{(, a} |
{*, +, ), $} |
4. Differentiate between LR(0) and LR(1) algorithm.
Difference between LR(0) and LR(1) algorithm
- LR(0)requires just the canonical items for the construction of a parsing table, but LR(1) requires the loookahead symbol as well.
- LR(1) allows us to choose the correct reductions and allows the use of grammar that are not uniquely invertible while LR(0) does not.
- LR(0) reduces at all items whereas LR(1) reduces only at lookahead symbols.
- LR(0) = canonical items and LR(1) = LR(0) + lookahead symbol.
- In canonical LR(0) collection, state/item is in the form:
E.g. I2 = { C → AB•}
whereas In cannonical LR(1) collection, state/item is in the form:
E.g. I2 = { C →d•, e/d} where e & d are lookahead symbol.
- Construction of canonical LR(0) collection starts with C = {closure({S‘→.S})} whereas Construction of canonical LR(1) collection starts with C = {closure({S‘→.S, $})} where S is the start symbol.
- LR(0) algorithm is simple than LR(1) algorithm.
- In LR(0), there may be conflict in parsing table while LL(1) parsing uses lookahead to avoid unnecessary conflicts in parsing table.
5. Construct LR(1) parse table for

The augmented grammar of given grammar is:
S' → S
S → XX
X → pX | q
Now, Canonical LR(1) item sets are:
I0 = closure([S' →•S, $]) = {[S' →•S, $], [S →•XX, $], [X → •pX, p/q], [X → •q, p/q]}
goto (I0, S) = closure([S' →•S, $]) = {[S'→ S•, $]} = I1
goto(I0, X) = closure([S → X•X, $] = {[S→X•X, $], [X→•pX, $], [X→•q, $]} = I2
goto(I0, p) = closure([X →p•X, p/q]) = {[X →p•X, p/q], [X →•pX, p/q], [X →•q, p/q]} = I3
goto(I0, q) = closure([X→q•, p/q]) = {[X→q•, p/q]} = I4
goto(I2, X) = closure ([S→XX•, $]) = {[S → XX •, $]} = I5
goto(I2, p) = closure([X→p•X, $]) = {[X → p•X, $], [X → • pX, $], [X → • q, $]} = I6
goto (I2, q) = closure ([X → q•, $]) = {[X → q•, $]} = I7
goto (I3, X) = closure ([X → pX•, p/q]) = {[X → pX•, p/q]} = I8
goto(I3, p) = closure([X →p•X, p/q]) = I3
goto(I3, q) = closure([X→q•, p/q]) = I4
goto(I6, X) = closure([X → pX•, $]) = {[X →pX•, $]} = I9
goto (I6, p) = closure([X→p•X, $]) = I6
goto(I6, q) = closure ([X → q•, $] = I7
Now, the LR(1) parsing table is,
1. S → XX
2. X → pX
3. X → q
|
States/ Terminals |
Action Table |
Goto Table |
|||
|
p |
q |
$ |
S |
X |
|
|
0 |
S3 |
S4 |
|
1 |
2 |
|
1 |
|
|
accept |
|
|
|
2 |
S6 |
S7 |
|
|
5 |
|
3 |
S3 |
S4 |
|
|
8 |
|
4 |
R4 |
R3 |
|
|
|
|
5 |
|
|
R1 |
|
|
|
6 |
S6 |
S7 |
|
|
9 |
|
7 |
|
|
R3 |
|
|
|
8 |
R2 |
R2 |
|
|
|
|
9 |
|
|
R2 |
|
|
6. How can syntax directed definition be used in type checking?
7. What is the theme of code optimization? Why is code optimization important in computer?
Code optimization is used to improve the intermediate code so that the output of the program could run faster and takes less space. It removes the unnecessary lines of the code and arranges the sequence of statements in order to speed up the program execution without wasting resources. It tries to improve the code by making it consume less resources (i.e. CPU, Memory) and deliver high speed. For e.g.
|
Intermediate code |
Optimized
Intermediate Code |
|
t1 = 3.0; t2 = id3 * t1; t3 = id2 + t2; id1 = t3; |
t2 = id3 * 3.0; id1 = id2 + t2; |
A code optimizing process must follow the three rules given below:
- The output code must not, in any way, change the meaning of the program.
- Optimization should increase the speed of the program and if possible, the program should demand less number of resources.
- Optimization should itself be fast and should not delay the overall compiling process.
Code optimization is important because:
- Code optimization enhances the portability of the compiler to the target processor.
- Code optimization allows consumption of fewer resources (i.e. CPU, Memory).
- Optimized code has faster execution speed.
- Optimized code utilizes the memory efficiently.
- Optimized code gives better performance.
- Optimized code often promotes re-usability.
8. Explain about peephole optimization with example.
Peephole optimization is a simple and effective technique for locally improving target code. This technique is applied to improve the performance of the target program by examining the short sequence of target instructions (called the peephole) and replace these instructions replacing by shorter or faster sequence whenever possible. Peephole is a small, moving window on the target program.
Peephole Optimization Techniques are:
1. Redundant load and store elimination: In this technique the redundancy is eliminated. For e.g.
Initial code:
y = x + 5;
i = y;
z = i;
w = z * 3;
Optimized code:
y = x + 5;
i = y;
w = y * 3;
Initial code:
x = 2 * 3;
Optimized code:
x = 6;
3. Strength Reduction: The operators that consume higher execution time are replaced by the operators consuming less execution time. For e.g.
Initial code:
y = x * 2;
Optimized code:
y = x + x;
4.
Algebraic Simplification: Peephole
optimization is an effective technique for algebraic simplification. The
statements such as x = x + 0 or x = x * 1 can eliminated by peephole
optimization.
5.
Machine idioms: The target
instructions have equivalent machine instructions for performing some
operations. Hence we can replace these target instructions by equivalent
machine instructions in order to improve the efficiency. For e.g., some machine
have auto-increment or auto-decrement addressing modes that are used to perform
add or subtract operations.
9. What are the advantages of intermediate code? Describe various representation of intermediate code.
The given program in a source language is converted into an equivalent program in an intermediate language by the intermediate code generator. Intermediate codes are machine independent codes.
Advantages of intermediate code:
- If a compiler translates the source language to its target machine language without having the option for generating intermediate code, then for each new machine, a full native compiler is required.
- Intermediate code eliminates the need of a new full compiler for every unique machine by keeping the analysis portion same for all the compilers.
- It becomes easier to apply the source code modifications to improve code performance by applying code optimization techniques on the intermediate code.
There are three kinds of intermediate code representations:
- Graphical representation (Syntax tree or DAGs)
- Postfix notations
- Three Address codes
Syntax Tree
Syntax tree is a graphic representation of given source program and it is also called variant of parse tree. A tree in which each leaf represents an operand and each interior node represents an operator is called syntax tree. For e.g. Syntax tree for the expression a+b*c-d/(b*c)

Directed Acyclic Graph (DAG)
A DAG for an expression identifies the common sub expressions in the expression. It is similar to syntax tree, only difference is that a node in a DAG representing a common sub expression has more than one parent, but in syntax tree the common sub expression would be represented as a duplicate sub tree. For e.g. DAG for the expression a+b*c-d/(b*c)

Postfix Notation
The representation of an expression in operators followed by operands is called postfix notation of that expression. In general if x and y be any two postfix expressions and OP is a binary operator then the result of applying OP to the x and y in postfix notation by "x y OP". For e.g. (a+ b) * c in postfix notation is: a b + c *
Three Address Code
The address code that uses at most three addresses, two for operands and one for result is called three address code. Each instruction in three address code can be described as a 4-tuple: (operator, operand1, operand2, result).
A quadruple (Three address code) is of the form: x = y op z where x, y and z are names, constants or compiler-generated temporaries and op is any operator.
For e.g.
The three-address code for a+b*c-d/(b*c)

10. Discuss the importance of symbol table in computer. How is it manipulated in the different phases of compilation?
Symbol table is an important data structure created and maintained by compilers in order to store information about the occurrence of various entities such as variable names, function names, objects, classes, interfaces, etc. Symbol table is used by both the analysis and the synthesis parts of a compiler.
A symbol table may serve the following purposes depending upon the language in hand:
- To store the names of all entities in a structured form at one place.
- To verify if a variable has been declared.
- To implement type checking, by verifying assignments and expressions in the source code are semantically correct.
- To determine the scope of a name (scope resolution).
It is used by various phases of compiler as follows:
- Lexical Analysis: Creates new table entries in the table, example like entries about token.
- Syntax Analysis: Adds information regarding attribute type, scope, dimension, line of reference, use, etc. in the table.
- Semantic Analysis: Uses available information in the table to check for semantics i.e. to verify that expressions and assignments are semantically correct (type checking) and update it accordingly.
- Intermediate Code generation: Refers symbol table for knowing how much and what type of run-time is allocated and table helps in adding temporary variable information.
- Code Optimization: Uses information present in symbol table for machine dependent optimization.
- Target Code generation: Generates code by using address information of identifier present in the table.