Compiler Design and Construction 2076
Attempt all questions. (10x6=60)
AI is thinking...
1. Explain briefly about different phases involved in compiler, with a block diagram.
A compiler operates in phases. A phase is a logically interrelated operation that takes source program in one representation and produces output in another representation. The phases of a compiler are shown in below:
1. Analysis phase breaks up the source program into constituent pieces and creates an intermediate representation of the source program. Analysis of source program includes: lexical analysis, syntax analysis and semantic analysis.
2. Synthesis phase construct the desired target program from the intermediate representation. The synthesis part of compiler consists of the following phases: Intermediate code generation, Code optimization and Target code generation.
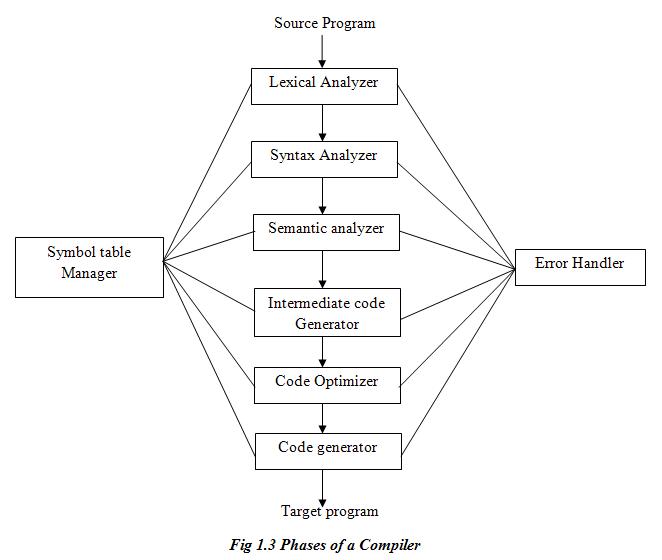
1. Lexical Analysis:
In this phase, lexical analyzer reads the source program and returns the tokens of the source program. Token is a sequence of characters that can be treated as a single logical entity (such as identifier, operators, keywords, constants etc.).
Example:
Input String: c = a + b * 3
Tokens: id1 = id2 + id3 * 3
2. Syntax Analysis:
In this phase, the syntax analyzer takes the token produced by lexical analyzer as input and generates a parse tree as output. In syntax analysis phase, the parser checks that the expression made by the token is syntactically correct or not, according to the rules that define the syntax of the source language.
Example:

3. Semantic Analysis:
In this phase, the semantic analyzer checks the source program for semantic errors and collects the type information for the code generation. Semantic analyzer checks whether they form a sensible set of instructions in the programming language or not. Type-checking is an important part of semantic analyzer.
Example:

4. Intermediate Code Generation:
If the program syntactically and semantically correct then intermediate code generator generates a simple machine independent intermediate language. The intermediate code should be generated in such a way that it can easily translated into the target machine code.
Example:
t1 = 3.0;
t2 = id3 * t1;
t3 = id2 + t2;
id1 = t3;
5. Code Optimization:
It is used to improve the intermediate code so that the output of the program could run faster and takes less space. It removes the unnecessary lines of the code and arranges the sequence of statements in order to speed up the program execution without wasting resources.
Example:
t2 = id3 * 3.0;
id1 = id2 + t2;
6. Code Generation:
Code generation is the final stage of the compilation process. It takes the optimized intermediate code as input and maps it to the target machine language.
Example:
MOV R1, id3
MUL R1, #3.0
MOV R2, id2
ADD R1, R2
MOV id1, R1
Symbol Table
Symbol tables are data structures that are used by compilers to hold information about source-program constructs. The information is collected incrementally by the analysis phase of compiler and used by the synthesis phases to generate the target code. Entries in the symbol table contain information about an identifier such as its type, its position in storage, and any other relevant information.
Error Handling
Whenever an error is encountered during the compilation of the source program, an error handler is invoked. Error handler generates a suitable error reporting message regarding the error encountered.
AI is thinking...
2. Given a regular expression (ε + 0)*10. Construct the DFA recognizing the pattern described by this regular expression using syntax tree based reduction.
Given RE;
(ε + 0)*10
The augmented RE of the given RE is:
(ε + 0)*10 #
Syntax tree for augmented R.E. is

Calculating followpos:
followpos(1) = {1, 2}
followpos(2) = {3}
followpos(3) = {4}
Now,
1) Start state of DFA = firstpos(root) = {1, 2} = S0
Use followpos of symbol representing position in RE to obtain the next state of DFA.
2) From S0 = {1, 2}
1 represents '0'
2 represents '1'
followpos(1) = {1, 2} = S0
δ(s0, 0) = S0
followpos(2) = {3} = S1
δ(S0, 1) = S1
3) From S1 = {3}
Here 3 represents '0'
followpos(3) = {4} = S2
δ(S1, 0) = S2
4) From S2 = {4}
Here 4 represents '#'
Now there was no new states occur.
Therefore, Final state = {S2}
Now the resulting DFA of given regular expression is:

AI is thinking...
3. What is shift reduce parsing techniques? Show shift reduce parsing action for the string (x+x)*a, given the grammar

The process of reducing the given input string into the starting symbol is called shift-reducing parsing.

A shift reduce parser uses a stack to hold the grammar symbol and an input buffer to hold the input string W.
Sift reduce parsing performs the two actions: shift and reduce.
- At the shift action, the current symbol in the input string is pushed to a stack.
- At each reduction, the symbols will replaced by the non-terminals. The symbol is the right side of the production and non-terminal is the left side of the production.
Now,
Given grammar;
Input String: (x+x)*a
Shift reduce parsing action for given input string is shown below:

At $S*a parser can neither perform shift action nor reduce action. Hence, error occurred.
AI is thinking...
4. Construct SLR parsing table for the following grammar.
S -> aAa | bAb | ba
AI is thinking...
5. Define Syntax directed definition. Construct annotated parse tree for the input expression (5*3+2)*5 according to the following syntax directed definition.
|
Production |
Semantic
Rule |
|
L
-> En |
Print
E.val |
|
E
-> E1 + T |
E.val
-> E1.val + T.val |
|
E
-> T |
E.val
->T.val |
|
T
-> T1 * F |
T.val
-> T1.val * F.val |
|
T
-> F |
T.val
-> F.val |
|
F
-> (E) |
F.val
-> (E.val) |
|
F
-> digit |
F.val
-> digit.lexval |
A syntax-directed definition (SDD) is a context-free grammar together with attributes and rules. Attributes are associated with grammar symbols and rules are associated with productions. For example,
|
Production
|
Semantic
Rules |
|
E → E1 + T |
E.val
= E1.val+T.val |
|
E → T |
E.val
= T.val |
The annotated parse tree for the input expression (5*3+2)*5 using given syntax directed definition is shown below:

AI is thinking...
6. Write Syntax Directed Definition to carry out type checking for the following expression.
E -> id | E1 op E2 | E1 relop E2 | E1[E2] | E1 ↑
E → id { E.type = lookup(id.entry) }
E → E1 op E2 { if (E1.type = integer and E2.type = integer) then E.type = integer
else if (E1.type = integer and E2.type = real) then E.type = real
else if (E1.type = real and E2.type = integer) then E.type = real
else if (E1.type = real and E2.type = real) then E.type = real
else E.type = type-error }
E → E1 relop E2 { if E1.type = boolean and E2.type = boolean then E.type = boolean
else E.type = error}
E → E1 [E2] { if (E2.type = int and E1.type = array(s, t)) then E.type = t
else E.type = type-error }
E →E1 ↑ { if E1.type = pointer(t) then E.type = t
else type-error}
AI is thinking...
7. Explain with example about different methods of intermediate code representation.
The given program in a source language is converted into an equivalent program in an intermediate language by the intermediate code generator. Intermediate codes are machine independent codes. There are three kinds of intermediate representations:
- Graphical representation (Syntax tree or DAGs)
- Postfix notations
- Three Address codes
Syntax Tree
Syntax tree is a graphic representation of given source program and it is also called variant of parse tree. A tree in which each leaf represents an operand and each interior node represents an operator is called syntax tree. For e.g. Syntax tree for the expression a+b*c-d/(b*c)

Directed Acyclic Graph (DAG)
A DAG for an expression identifies the common sub expressions in the expression. It is similar to syntax tree, only difference is that a node in a DAG representing a common sub expression has more than one parent, but in syntax tree the common sub expression would be represented as a duplicate sub tree. For e.g. DAG for the expression a+b*c-d/(b*c)

Postfix Notation
The representation of an expression in operators followed by operands is called postfix notation of that expression. In general if x and y be any two postfix expressions and OP is a binary operator then the result of applying OP to the x and y in postfix notation by "x y OP". For e.g. (a+ b) * c in postfix notation is: a b + c *
Three Address Code
The address code that uses at most three addresses, two for operands and one for result is called three address code. Each instruction in three address code can be described as a 4-tuple: (operator, operand1, operand2, result).
A quadruple (Three address code) is of the form: x = y op z where x, y and z are names, constants or compiler-generated temporaries and op is any operator.
For e.g.
The three-address code for a+b*c-d/(b*c)

AI is thinking...
8. What is the purpose of code optimization? Explain different types of loop optimization techniques with example.
Code optimization is used to improve the intermediate code so that the output of the program could run faster and takes less space. It removes the unnecessary lines of the code and arranges the sequence of statements in order to speed up the program execution without wasting resources. It tries to improve the code by making it consume less resources (i.e. CPU, Memory) and deliver high speed.
Loop Optimization techniques are given below:
1. Frequency Reduction (Code Motion): In frequency reduction, the amount of code in loop is decreased. A statement or expression, which can be moved outside the loop body without affecting the semantics of the program, is moved outside the loop. For e.g.
Before optimization: while(i<100) { a = Sin(x)/Cos(x) + i; i++; } | After optimization: t = Sin(x)/Cos(x); while(i<100) { a = t + i; i++; } |
2. Loop Unrolling: In this technique the number of jumps and tests can be optimized by writing the code to times without changing the meaning of a code. For e.g.
Before optimization: int i = 1; while(i<100) { a[i] = b[i]; i++; }
| After optimization: int i = 1; while(i<100) { a[i] = b[i]; i++; a[i] = b[i]; i++; } |
The first code loop repeats 50 times whereas second code loop repeats 25 times. Hence, optimization is done.
3. Loop Fusion/Loop Jamming: This technique combines the bodies of two loops whenever the same index variable and number of iterations are shared. For e.g.
Before optimization: for(i=0;i<=10;i++) { Printf(“Jayanta”); } for(i=0;i<=10;i++) { Printf(“Poudel”); } | After optimization: for(i=0;i<=10;i++) { Printf(“Jayanta”); Printf(“Poudel”); }
|
4. Reduction in Strength: The strength of certain operators is higher than other operators. For example, strength of * is higher than +. Usually, compiler takes more time for higher strength operators and execution speed is less. Replacement of higher strength operator by lower strength operator is called a strength reduction technique
Optimization can be done by applying strength reduction technique where higher strength can be replaced by lower strength operators. For e.g.
Before optimization: for (i=1;i<=10;i++) { sum = i * 7; printf(“%d”, sum); }
| After optimization: temp = 7; for(i=1;i<=10;i++) { temp = temp + 7; sum = temp; printf(“%d”, sum) } |
AI is thinking...
9. Discuss about different factors affecting the process of target code generation.
The final phase in compiler model is the code generator. It takes as input an intermediate representation of the source program and produces as output an equivalent target program. Designing of code generator should be done in such a way so that it can be easily implemented, tested and maintained.
The different factors affecting target code generation includes:
1. Input to the code generator: The input to the code generator is intermediate representation together with the information in the symbol table. Intermediate representation has the several choices:
- Postfix notation,
- Syntax tree or DAG,
- Three address code
The code generation phase needs complete error-free intermediate code as an input requires.
2. Target Program: The target program is the output of the code generator. The output can be:
- Assembly language: It allows subprogram to be separately compiled.
- Relocatable machine language: It makes the process of code generation easier.
- Absolute machine language: It can be placed in a fixed location in memory and can be executed immediately.
3. Target Machine: Implementing code generation requires thorough understanding of the target machine architecture and its instruction set.
4. Instruction Selection: Efficient and low cost instruction selection is important to obtain efficient code. When we consider the efficiency of target machine then the instruction speed and machine idioms are important factors. The quality of the generated code can be determined by its speed and size.
5. Register Allocation: Proper utilization of registers improve code efficiency. Use of registers make the computations faster in comparison to that of memory, so efficient utilization of registers is important. The use of registers are subdivided into two subproblems:
- During Register allocation, we select only those set of variables that will reside in the registers at each point in the program.
- During a subsequent Register assignment phase, the specific register is picked to access the variable.
6. Choice of Evaluation order: The efficiency of the target code can be affected by the order in which the computations are performed.
AI is thinking...
10. Discuss the importance of error handler in compiler. How is it manipulated in the different phases of compilation?
Error detection and reporting of errors are important functions of the compiler. Whenever an error is encountered during the compilation of the source program, an error handler is invoked. Error handler generates a suitable error reporting message regarding the error encountered. The error reporting message allows the programmer to find out the exact location of the error. Errors can be encountered at any phase of the compiler during compilation of the source program for several reasons such as:
- In lexical analysis phase, errors can occur due to misspelled tokens, unrecognized characters, etc. These errors are mostly the typing errors.
- In syntax analysis phase, errors can occur due to the syntactic violation of the language.
- In intermediate code generation phase, errors can occur due to incompatibility of operands type for an operator.
- In code optimization phase, errors can occur during the control flow analysis due to some unreachable statements.
- In code generation phase, errors can occurs due to the incompatibility with the computer architecture during the generation of machine code. For example, a constant created by compiler may be too large to fit in the word of the target machine.
- In symbol table, errors can occur during the bookkeeping routine, due to the multiple declaration of an identifier with ambiguous attributes.
After detecting an error, a phase must somehow deal with that error, so that compilation can proceed, allowing further errors in the source program to be detected.
Error handler contains a set of routines for handling error encountered in any phase of the compiler. Every phase of compiler will call an appropriate routine of the error handler as per their specifications.
AI is thinking...