Data Structures and Algorithms 2072
Section A
AI is thinking...
Attempt any TWO questions: (2x10=20)
AI is thinking...
1. What is binary search tree? Explain with an example. Write an algorithm to search, insert and delete node in binary search tree.
A binary search tree (BST) is a binary tree that is either empty or in which every node contains a key (value) and satisfies the following conditions:
- All keys in the left sub-tree of the root are smaller than the key in the root node
- All keys in the right sub-tree of the root are greater than the key in the root node
- The left and right sub-trees of the root are again binary search trees
Example:
Given the following sequence of numbers,
14, 4, 15, 3, 9, 14, 18
The following binary search tree can be constructed:

Algorithm to search the element in BST
void BinSearch(struct bnode *root , int key)
{
if(root == NULL)
{
printf(“The number does not exist”);
exit(1);
}
else if (key == root->info)
{
printf(“The searched item is found”):
}
else if(key < root->info)
return BinSearch(root->left, key);
else
return BinSearch(root->right, key);
}
Algorithm to insert the element in BST
void insert(struct bnode *root, int item)
{
if(root=NULL)
{
root=(struct bnode*)malloc (sizeof(struct bnode));
root->left=root->right=NULL;
root->info=item;
}
else
{
if(item<root->info)
root->left=insert(root->left, item);
else
root->right=insert(root->right, item);
}
}
Algorithm to delete the element in BST
struct bnode *delete(struct bnode *root, int item)
{
struct bnode *temp;
if(root==NULL)
{
printf(“Empty tree”);
return;
}
else if(item<root->info)
root->left=delete(root->left, item);
else if(item>root->info)
root->right=delete(root->right, item);
else if(root->left!=NULL &&root->right!=NULL) //node has two child
{
temp=find_min(root->right);
root->info=temp->info;
root->right=delete(root->right, root->info);
}
else
{
temp=root;
if(root->left==NULL)
root=root->right;
else if(root->right==NULL)
root=root->left;
free(temp);
}
return(temp);
}
Finding minimum element function:
struct bnode *find_min(struct bnode *root)
{
if(root==NULL)
return0;
else if(root->left==NULL)
return root;
else
return(find_min(root->left));
}
AI is thinking...
2. What is Postfix expression? Write an algorithm to evaluate value of postfix expression. Trace the following expression into postfix expression.
(A+B*C)+(D-E/ F)
The expression in which operator is written in after the operands is called postfix expression. For example: AB+
Algorithm to evaluate value of postfix expression
1. Create a stack to store operands.
2. Scan the given expression from left to right.
3. a) If the scanned character is an operand, push it into the stack.
b) If the scanned character is an operator, POP 2 operands from stack and perform operation and PUSH the result back to the stack.
4. Repeat step 3 till all the characters are scanned.
5. When the expression is ended, the number in the stack is the final result.
Given,
infix expression = (A+B*C)+(D-E/ F)
Now, converting it into postfix:
|
Characters |
stack |
Postfix expression |
|
( |
( |
|
|
A |
( |
A |
|
+ |
(+ |
A |
|
B |
(+ |
AB |
|
* |
(+* |
AB |
|
C |
(+* |
ABC |
|
) |
|
ABC*+ |
|
+ |
+ |
ABC*+ |
|
( |
+( |
ABC*+ |
|
D |
+( |
ABC*+D |
|
- |
+(- |
ABC*+D |
|
E |
+(- |
ABC*+DE |
|
/ |
+(-/ |
ABC*+DE |
|
F |
+(-/ |
ABC*+DEF |
|
) |
+ |
ABC*+DEF/- |
|
|
|
ABC*+DEF/-+ |
The postfix expression of given infix expression is: A B C * + D E F / - +
AI is thinking...
3. What is circular queue? Write an algorithm and C function to implement Circular queue.
Circular Queue is a linear data
structure in which the operations are performed based on FIFO (First In First
Out) principle and the last position is connected back to the first position to
make a circle.
Graphical representation of a circular queue is as follows:

Initialization of
Circular queue:
rear=front=MAXSIZE-1
Algorithms for inserting an element in a circular queue:
This
algorithm is assume that rear and front are initially set to MAZSIZE-1.
1.
if (front==(rear+1)%MAXSIZE)
print Queue is full and exit
else
rear=(rear+1)%MAXSIZE; [increment rear by 1]
2.
cqueue[rear]=item;
3.
end
Algorithms for deleting an element from a circular queue:
This
algorithm is assume that rear and front are initially set to MAZSIZE-1.
1.
if (rear==front) [checking empty condition]
print Queue is empty and exit
2.
front=(front+1)%MAXSIZE; [increment front by 1]
3.
item=cqueue[front];
4.
return item;
5. end.
#include<stdio.h>
#include<conio.h>
#define
SIZE 5
void
enQueue(int);
void
deQueue();
void
display();
int
cQueue[SIZE], front = -1, rear = -1;
void
main()
{
int choice, value;
clrscr();
while(1){
printf("\\n****** MENU
******\\n");
printf("1. Insert\\n2. Delete\\n3.
Display\\n4. Exit\\n");
printf("Enter your choice: ");
scanf("%d",&choice);
switch(choice){
case 1: printf("\\nEnter the value to be
insert: ");
scanf("%d",&value);
enQueue(value);
break;
case 2: deQueue();
break;
case 3: display();
break;
case 4: exit(0);
default: printf("\\nPlease select the
correct choice!!!\\n");
}
}
}
void
enQueue(int value)
{
if((front == 0 && rear == SIZE - 1)
|| (front == rear+1))
printf("\\nCircular Queue is Full!
Insertion not possible!!!\\n");
else{
if(rear == SIZE-1 && front != 0)
rear = -1;
cQueue[++rear] = value;
printf("\\nInsertion
Success!!!\\n");
if(front == -1)
front = 0;
}
}
void
deQueue()
{
if(front == -1 && rear == -1)
printf("\\nCircular Queue is Empty!
Deletion is not possible!!!\\n");
else{
printf("\\nDeleted element :
%d\\n",cQueue[front++]);
if(front == SIZE)
front = 0;
if(front-1 == rear)
front = rear = -1;
}
}
void
display()
{
if(front == -1)
printf("\\nCircular Queue is
Empty!!!\\n");
else{
int i = front;
printf("\\nCircular Queue Elements
are : \\n");
if(front <= rear){
while(i <= rear)
printf("%d\\t",cQueue[i++]);
}
else{
while(i <= SIZE - 1)
printf("%d\\t", cQueue[i++]);
i
= 0;
while(i <= rear)
printf("%d\\t",cQueue[i++]);
}
}
}
AI is thinking...
Section B
AI is thinking...
Attempt any EIGHT questions: (8x5=40)
AI is thinking...
4. What is Recursion? Write a recursive algorithm to implement binary search.
Recursion is a process by which a function calls itself repeatedly, until some specified condition has been satisfied. The process is used for repetitive computations in which each action is stated in terms of a previous result.
Recursive algorithm to implement binary search
int binarySearch(int A[], int low, int high, int x)
{
if (low > high) {
return -1;
}
int mid = (low + high) / 2;
if (x == A[mid]) {
return mid;
}
else if (x < A[mid]) {
return binarySearch(A, low, mid - 1, x);
}
else {
return binarySearch(A, mid + 1, high, x);
}
}
AI is thinking...
5. Differentiate between array and pointer with example.
Array in C is used to store elements of same types whereas Pointers are address variables which stores the address of a another variable. Now array variable is also having a address which can be pointed by a pointer and array can be navigated using pointer. Benefit of using pointer for array is two folds, first, we store the address of dynamically allocated array to the pointer and second, to pass the array to a function. Following are the differences in using array and using pointer to array.
- sizeof() operator prints the size of array in case of array and in case of pointer, it prints the size of int.
- assignment array variable cannot be assigned address of another variable but pointer can take it.
- first value first indexed value is same as value of pointer. For example, array[0] == *p.
- iteration array elements can be navigated using indexes using [], pointer can give access to array elements by using pointer arithmetic. For example, array[2] == *(p+2)
Example:
#include <stdio.h>
void printElement(char* q, int index){
printf("Element at index(%d) is: %c\\n", index, *(q+index));
}
int main() {
char arr[] = {'A', 'B', 'C'};
char* p = arr;
printf("Size of arr[]: %d\\n", sizeof(arr));
printf("Size of p: %d\\n", sizeof(p));
printf("First element using arr is: %c\\n", arr[0]);
printf("First element using p is: %c\\n", *p);
printf("Second element using arr is: %c\\n", arr[1]);
printf("Second element using p is: %c\\n", *(p+1));
printElement(p, 2);
return 0;
}Output:
Size of arr[]: 3
Size of p: 8
First element using arr is: A
First element using p is: A
Second element using arr is: B
Second element using p is: B
Element at index(2) is: C
AI is thinking...
6. What is an algorithm? Write down the features of an algorithm.
An algorithm is a sequence of unambiguous instructions used for solving a problem, which can be implemented (as a program) on a computer
Algorithms are used to convert our problem solution into step by step statements. These statements can be converted into computer programming instructions which forms a program. This program is executed by computer to produce solution. Here, program takes required data as input, processes data according to the program instructions and finally produces result as shown in the following picture

Features of algorithm:
- Input - Every algorithm must take zero or more number of input values from external.
- Output - Every algorithm must produce an output as result.
- Definiteness - Every statement/instruction in an algorithm must be clear and unambiguous (only one interpretation)
- Finiteness - For all different cases, the algorithm must produce result within a finite number of steps.
- Effectiveness - Every instruction must be basic enough to be carried out and it also must be feasible.
- Correctness: Correct set of output values must be produced from the each set of inputs.
AI is thinking...
7. How stack as ADT? Explain with example.
A stack is an ordered collection of items into which new items may be inserted and from which items may be deleted at one end, called the top of the stack. The deletion and insertion in a stack is done from top of the stack.
It is a linear data structure which store data temporarily to perform PUSH and POP operation in LIFO (Last-In-First-Out) sequence.
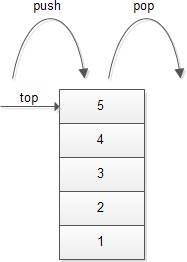
Fig::A stack containing items or elements
Stack as ADT
A stack of elements of type T is a finite sequence of elements of T together with the operations
- CreateEmptyStack(S): Create or make stack S be an empty stack
- Push(S, x): Insert x at one end of the stack, called its top
- Top(S): If stack S is not empty; then retrieve the element at its top
- Pop(S): If stack S is not empty; then delete the element at its top
- IsFull(S): Determine if S is full or not. Return true if S is full stack; return false otherwise
- IsEmpty(S): Determine if S is empty or not. Return true if S is an empty stack; return false otherwise.
Thus by using a stack we can perform above operations thus a stack acts as an ADT.
AI is thinking...
8. Write an algorithm and C function to delete node in singly link list.
An algorithm to deleting the first node of the singly linked list:
let *head be the pointer to first node in the current list
1. Create a new node using malloc function
NewNode=(NodeType*)malloc(sizeof(NodeType));
2. Assign data to the info field of new node
NewNode->info=newItem;
3. Set next of new node to head
NewNode->next=head;
4. Set the head pointer to the new node
head=NewNode;
5. End
C function:
void deleteBeg()
{
NodeType *temp;
if(head==NULL)
{
printf(“Empty list”);
exit(1).
}
else
{
temp=head;
printf(“Deleted item is %d” , head->info);
head=head->next;
free(temp);
}
}
An algorithm to deleting the last node of the singly linked list:
let *head be the pointer to first node in the current list
1. If(head==NULL) then //if list is empty
print “Void deletion” and exit
2. else if(head->next==NULL) then //if list has only one node
Set temp=head;
print deleted item as,
printf(“%d” ,head->info);
head=NULL;
free(temp);
3. else
set temp=head;
while(temp->next->next!=NULL)
set temp=temp->next;
End of while
free(temp->next);
Set temp->next=NULL;
4. End
C Function:
void deleteEnd()
{
NodeType *temp;
if(head==NULL)
{
printf(“Empty list”);
return;
}
else if(head->next==NULL)
{
temp=head;
head=NULL;
printf(“Deleted item is %d”, temp->info);
free(temp);
}
else
{
temp=head;
while(temp->next->next!=NULL)
{
temp=temp->next;
}
printf(“deleted item is %d'” , temp->next->info):
free(temp->next);
temp->next=NULL;
}
}
AI is thinking...
9. Write an algorithm and C function for merge sort.
The basic concept of merge sort is divides the list into two smaller sub-lists of approximately equal size. Recursively repeat this procedure till only one element is left in the sub-list. After this, various sorted sub-lists are merged to form sorted parent list. This process goes on recursively till the original sorted list arrived.
Procedure
To sort A[l………….r]
1. Divide step: If a given array A has zero or one element, simply return; it is already sorted. Otherwise split A[l……….r] into two sub-arrays A[l………q] and A[q+1…………r] each containing about half of the element A[l…….r]. that is q is the half of way point of A[l…….r].
2. Conquer step: Sorting the two sub-arrays A[l………q] and A[q+1…………r] recursively. When the size of sequence of is 1 there is nothing more to do.
3. Combine step: combine the two sub-arrays A[l……q] and A[q+1…………r] into a sorted sequence.
C function
MergeSort(A, l, r)
{
If ( l < r)
{
m = (l + r)/2
MergeSort(A, l, m)
MergeSort(A, m + 1, r)
Merge(A, l, m+1, r)
}
}
Merge(A, B, l, m, r)
{
x=l, y=m;
k=l;
while(x<m && y<r)
{
if(A[x] < A[y])
{
B[k]= A[x];
k++;
x++;
}
else
{
B[k] = A[y];
k++;
y++;
}
AI is thinking...
10. What do you mean by graph traversal? Explain prim's algorithm with example.
Traversing a graph means visiting all the vertices in a graph exactly one. In graph all nodes are treated equally. So the starting nodes in graph can be chosen arbitrarily.
A graph traversal finds the edges to be used in the search process without creating loops that means using graph traversal we visit all vertices of graph without getting into looping path.
Prim’s Algorithm
Prim's Algorithm is used to find the minimum spanning tree from a graph. Prim's algorithm finds the subset of edges that includes every vertex of the graph such that the sum of the weights of the edges can be minimized.
This algorithm involves the
following steps:
1. Select any vertex in G. Among all the edges which are
incident to it, choose an edge of minimum weight. Include it in T.
2. At each stage, choose an edge of smallest weight joining
a vertex which is already included in T and a vertex which is not included yet
so that it does not form a cycle. Then included it in T.
3. Repeat until all the vertices of G are included with n-1 edges.
Pseudocode:
T = ∅;
U = { 1 };
while (U ≠ V)
let (u, v) be the lowest cost edge such that u ∈ U and v ∈ V - U;
T = T ∪ {(u, v)}
U = U ∪ {v}AI is thinking...
11. Differentiate between selection sort and bubble sort.
Bubble Sort:
This sorting technique is also known as exchange sort, which arranges values by iterating over the list several times and in each iteration the larger value gets bubble up to the end of the list. This algorithm uses multiple passes and in each pass the first and second data items are compared. if the first data item is bigger than the second, then the two items are swapped. Next the items in second and third position are compared and if the first one is larger than the second, then they are swapped, otherwise no change in their order. This process continues for each successive pair of data items until all items are sorted.
AI is thinking...
12. Write an algorithm to implement tower of Hanoi.
Tower of Hanoi (TOH) is a mathematical puzzle which consists of three pegs named as origin, intermediate and destination and more than one disks. These disks are of different sizes and the smaller one sits over the larger one.
In this problem we transfer all disks from origin peg to destination peg using intermediate peg for temporary storage and move only one disk at a time.

Algorithm for TOH problem:
Let’s consider move ‘n’ disks from source peg (A) to destination peg (C), using intermediate peg (B) as auxiliary.
1. Assign three pegs A, B & C
2. If n==1
Move the single disk from A to C and stop.
3. If n>1
a) Move the top (n-1) disks from A to B.
b) Move the remaining disks from A to C
c) Move the (n-1) disks from B to C
4. Terminate
Example for 3 disks: 7 moves

AI is thinking...
13. Write short notes on
a) Hashing
b) Doubly Linked list
a) Hashing
Hashing is a well-known technique to search any particular element among several elements. It minimizes the number of comparisons while performing the search.
In hashing, an array data structure called as Hash table is used to store the data items. Hash table is a data structure used for storing and retrieving data very quickly. Insertion of data in the hash table is based on the key value. Hence every entry in the hash table is associated with some key. Using the hash key the required piece of data can be searched in the hash table by few or more key comparisons.

Fig: Hashing Mechanism
Hash function is a function which is used to put the data in the hash table. Hence one can use the same hash function to retrieve the data from the hash table. Thus hash function is used to implement the hash table. The integer returned by the hash function is called hash key.
E.g. Division Hash Function
The division hash function depends upon the remainder of division. Typically the divisor is table length. For e.g. If the record 54, 72, 89, 37 is placed in the hash table and if the table size is 10 then the hash function is:
h(key) = record % table size
and key obtained by hash function is called hash key.
54%10=4
72%10=2
89%10=9
37%10=7

b) Doubly Linked List
Doubly linked list is a sequence of elements in which every element has links to its previous element and next element in the sequence.
In double linked list, every node has link to its previous node and next node. So, we can traverse forward by using next field and can traverse backward by using previous field. Every node in a double linked list contains three fields and they are shown in the following figure...

Here, 'link1' field is used to store the address of the previous node in the sequence, 'link2' field is used to store the address of the next node in the sequence and 'data' field is used to store the actual value of that node.
Example:

AI is thinking...